0
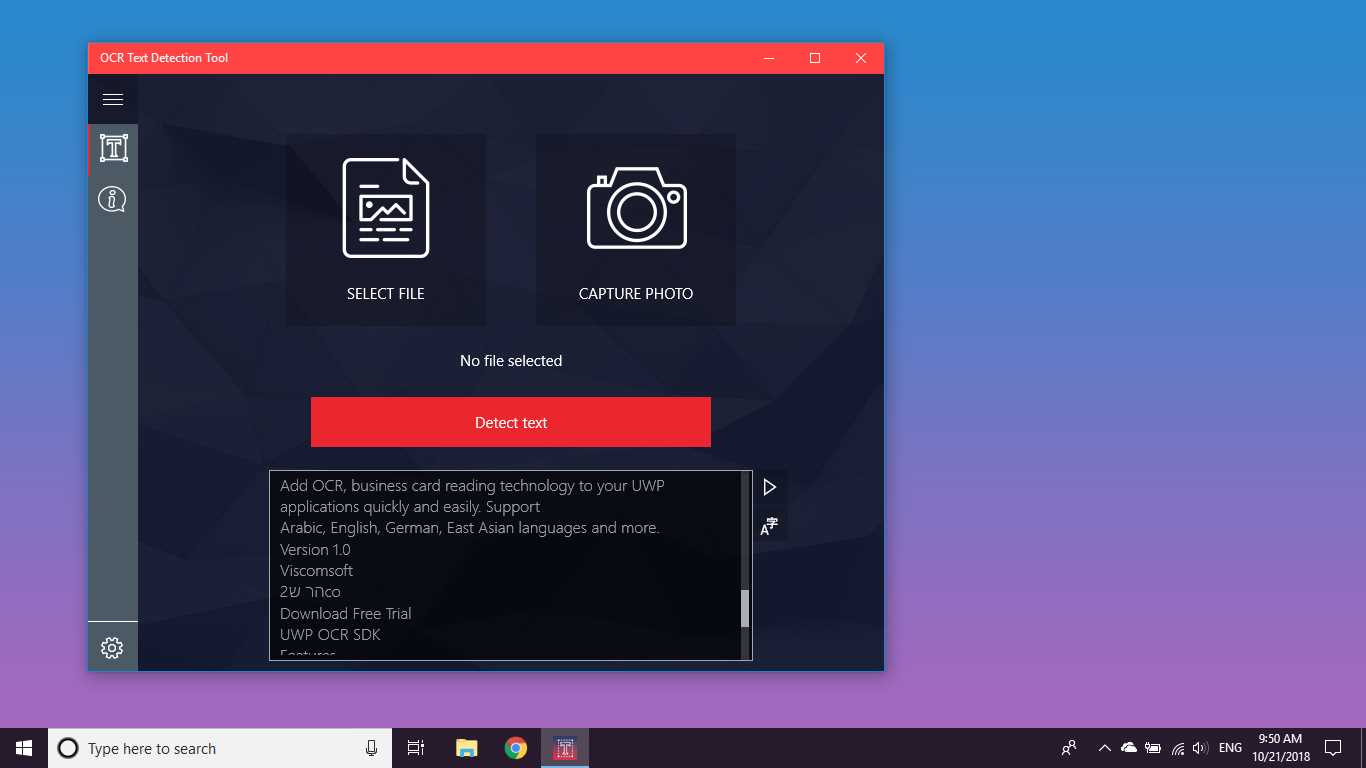
OCR Text Detection Tool
Omogućuje precizno i brzo otkrivanje teksta iz bilo koje slikovne datoteke preuzete s vašeg uređaja ili snimljenu snimkom.Također podržava tekstualno otkrivanje PDF-a i otkrivanje teksta na rukopisu i prijevod teksta na 114 različitih jezika.
- Besplatna
- Windows S
- Windows
- Windows Mobile
- Windows Phone
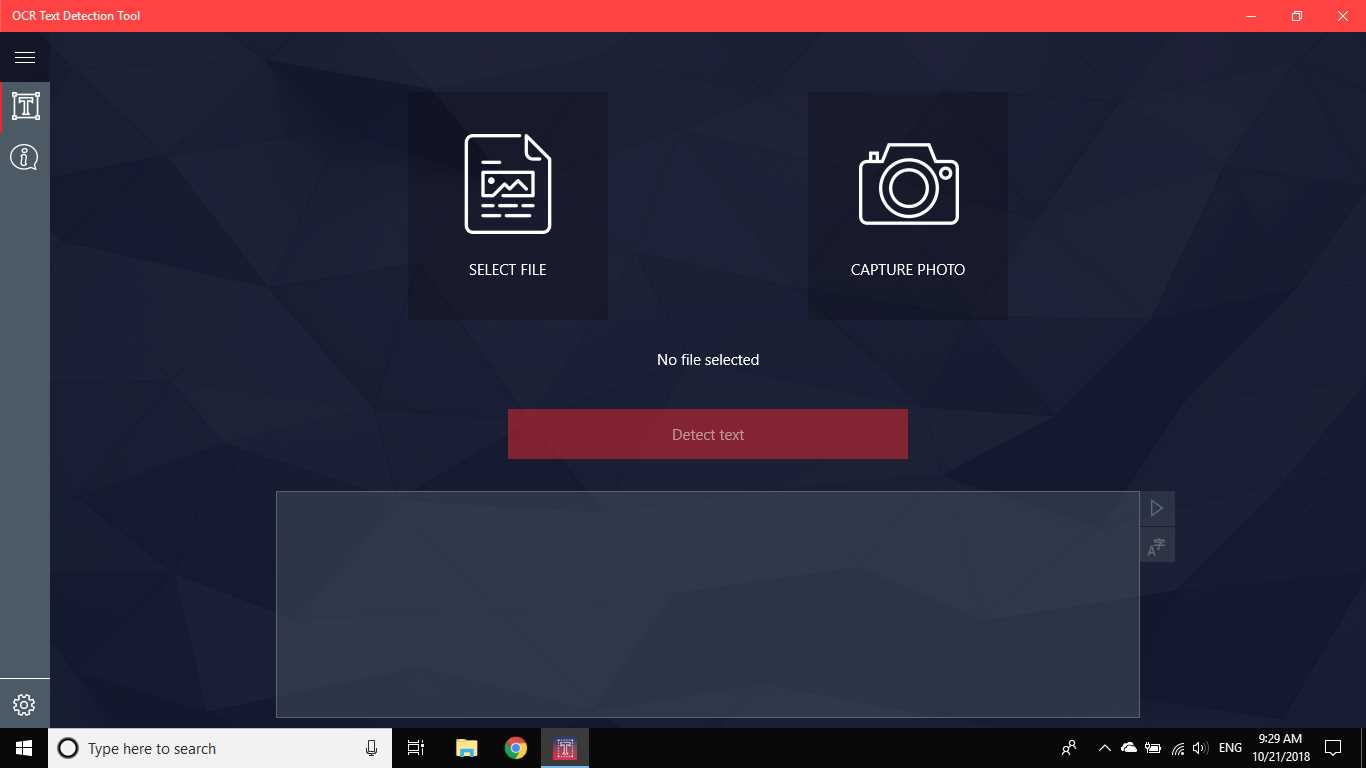
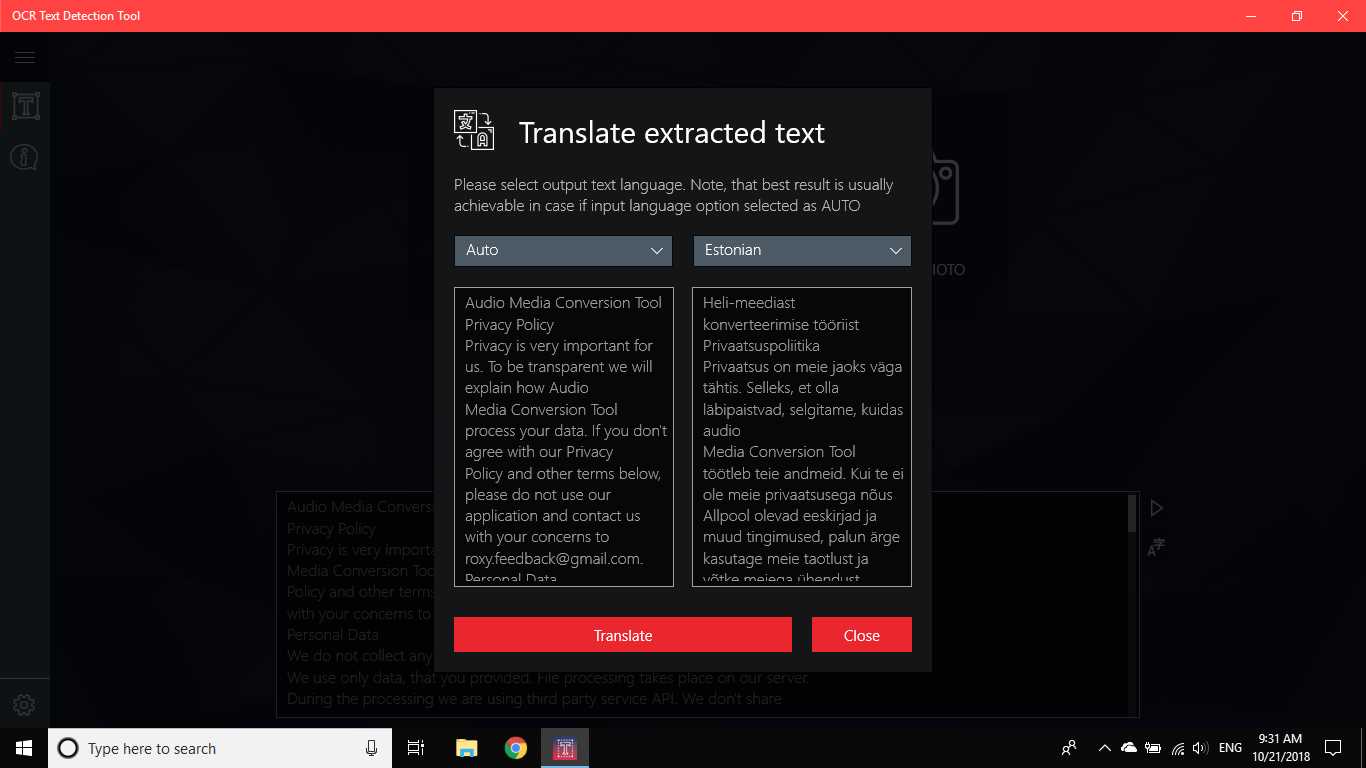
OCR Alat za otkrivanje teksta omogućuje precizno i brzo otkrivanje teksta iz bilo koje slikovne datoteke preuzete s vašeg uređaja ili snimljene snimkom.Podržava i tekstualno otkrivanje PDF dokumenta (trenutno ne više od 20 stranica, ali radimo na proširenju funkcionalnosti).Aplikacija također podržava prepoznavanje rukopisa na temelju teksta i prijevod teksta na 114 različitih jezika.Prijatan, jasan i praktičan dizajn čini rad s aplikacijom jednostavnim i razumljivim.* Dostupni formati: JPEG, PNG8, PNG24, GIF, animirani GIF (samo prvi okvir), BMP, WEBP, RAW, ICO, TIFF, PDF (trenutno ne više od 20 stranica, ali radimo na proširenju funkcionalnosti) * Tekstznačajka prepoznavanja može otkriti širok raspon jezika i može otkriti više jezika unutar jedne slike: afrički (af), arapski (ar), asamski (kao), azerbejdžanski (az), bjeloruski (biti), bengalski (bn), Bugarski (bg), katalonski (ca), kineski (zh *), hrvatski (hr), češki (cs), danski (da), nizozemski (nl), engleski (en), estonski (et), filipinski (fil)ili tl), finski (fi), francuski (fr), njemački (de), grčki (el), hebrejski (on ili iw), hindski (hi), mađarski (hu), islandski (is), indonezijski (id), Talijanski (it), japanski (ja), kazahstanski (kk), korejski (ko), kirgiski (ky), latvijski (lv), litvanski (lt), makedonski (mk), marati (mr), mongolski (mn), Nepalski (ne), norveški (ne), paštu (ps), perzijski (fa), poljski (pl), portugalski (pt), rumunjski (ro), ruski (ru), sanskrit (sa), srpski (sr), Slovački (sk), slovenski (sl), španjolski (i), švedski (sv), tamilski (ta), tajlandski (th), turski (tr), ukrajinski (uk), urdu (ur), uzbečki (uz), vijetnamski (vi) Provjerite, nemate što izgubiti!
Web stranica:
https://www.microsoft.com/store/apps/9PL1PPFPT8VJZnačajke
Kategorije
Alternativa OCR Text Detection Toolu za Linux
71
35
GImageReader
gImageReader je jednostavan Gtk / Qt prednji dio Tesseract OCR motora. Značajke: - Uvoz PDF dokumenata i slika s diska, uređaja za skeniranje, međuspremnik i snimke zaslona
9
8
6
5
5
4